
Diesmal ein ziemlich spezielles Maven Thema. Für eines meiner Projekte habe ich mir mal näher den inneren Aufbau vom Suchindex von Maven angeschaut.
Prinzipiell kann man dafür natürlich Lucene und das Luce Tool verwenden, aber das ist auch nicht so schnell "out of the Box" möglich, aber ich zeige weiter unten wie es geht. Nein ich schreibe das Projekt in C#, und wollte möglichst wenig auf Java-Bibliotheken zurückgreifen, da eine Anbindung derselben fehleranfällig ist. Ich gebe euch mal einen kurzen Überblick über das:
Maven Repository
Prinzipiell ist es sehr einfach aufgebaut, wie wir uns am Beispiel vom Apache-Repo (https://repo.maven.apache.org/) anschauen. Zum einen haben wir da das Hauptverzeichnis https://repo.maven.apache.org/maven2/, welches hier am wichtigsten eine "last_updated.txt" Datei, welche den letzten Stand enthält. Die "archetype-catalog.xml" im Verzeichnis beinhaltet leider nicht alle Projekte, somit ist der für uns uninteressant. Einer rein, kommt man dann zu den einzelnen Paketen. zum Beispiel liegt das rest-Paket von Spring boot (org.springframework.boot.spring-boot-starter-data-rest) eben unter org/springframework/boot/spring-boot-starter-data-rest/. Also im Prinzip nur die POunkte durch "/" ersetzt. In diesem Ordner findet man nun eine Datei mit dem Überblick aller Versionen und der neusten Version ("maven-metadata.xml").
Wenn man zu alle dem nun einem Suchprojekt schreiben wollte, dann müsste man ja das komplette Repo parsen, da es keine zentrale Datei mit einem Überblick gibt (wie gesagt die "archetype-catalog.xml" enthält nicht alle Infos.) Es gibt aber noch einen versteckten Ordner:
Maven Repository Index
Dieser befindet sich unter: https://repo.maven.apache.org/maven2/.index/. Hier liegen die eigentlich gesuchten Informationen. Ein kurzer Blick auf die Apache-Webseite zeigt das, um die Daten zu verwenden, sie zualler erst umgewandelt werden müssen: Dazu lädt man die vollständige Index-Datei ("nexus-maven-repository-index.gz"), und entpackt diese. Es handelt sich um eine riesige Datei, und wer schonmal ein Lucene Index Ordner gesehen hat, weiß, das ist nicht das Lucene Format. Um das wiederum zu bekommen, benötigt man das Tool "Maven Indexer Cli"gund kann mit Hilfe des Tools mit
java -jar indexer-cli-5.1.1.jar --unpack nexus-maven-repository-index.gz --destination central-lucene-index --type fullDen Index wieder zusammenbauen. Am Ende enthält man ein Verzeichnis mit einen Haufen Dateien (einen Lucene Index), welcher noch größer als die Eingabedatei ist. Man kann sagen, das es sich bei der Eingabedatei um ein "kompaktes Format" handelt (es sind nur die Stammdaten, aber nicht der Index selber enthalten), und bei dem Ausgabeverzeichnis handelt es sich dann um das vollständige Format (Lucene Format). Ein Wort noch zum "kompakten Format": man kann damit zwar nicht sinnvoll suchen, aber es ist fähig inkrementell zusammengesetzt zu werden, also ideal als Transportformat
Luce Tool
Das Lucene Format kann man mit dem Luce Tool lesen. Wichtig ist die 4er Version des Luce-Tools zu verwenden. Mit 4.10.4 kann man das Verzeichnis problemlos laden (https://github.com/DmitryKey/luke/releases/tag/luke-4.10.4). Mit diesem Tool kann man sich nun einen Überblick über den Inhalt des Indexes gewinnen. Starten tut man es mit folgender Batch:
@echo off
set JAVA_OPTIONS=%JAVA_OPTIONS% -XX:MaxPermSize=512m
start javaw %JAVA_OPTIONS% -jar .\target\luke-with-deps.jar
Beim Pfad muss natürlich ein Verzeichnis angegeben werden, keine Datei. In der Übersicht des Tools sieht man die enthaltenen Felder:
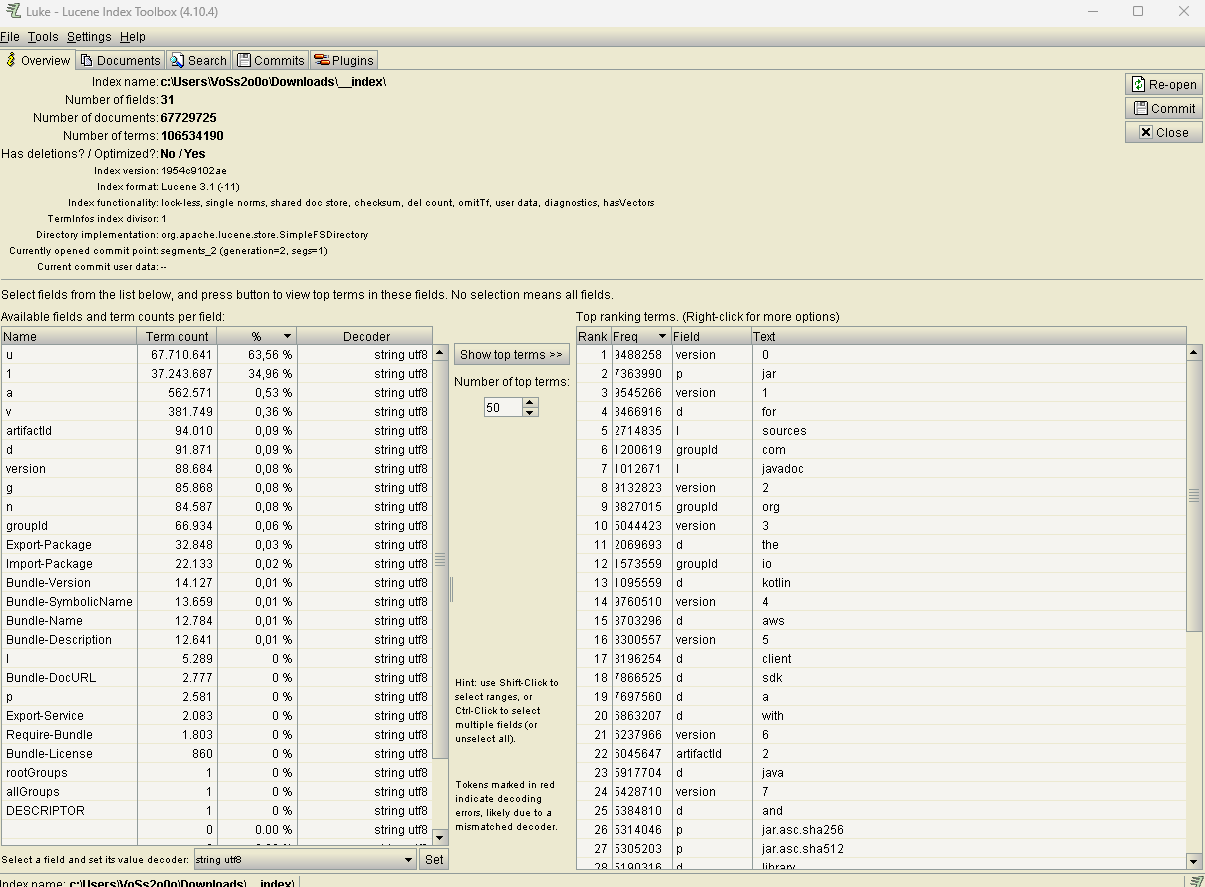
Die Maven Index Felder (Sonartype Nexus)
Folgende Felder sollten (der Wichtigkeit nach sortiert) enthalten sein:
- u: enthält <groupId>|<artefactID>|<Version>|<PackageType>
- n: enthält den Namen
- d: enthält die beschreibung
- i: enthält verschiedene Informationen mit Pipe getrennt
- 1: enthält den Hash
- Bundle-Name: Name, wenn es sich um ein Bundle handelt
- Bundle-Description: Beschreibung bei einem Bundle
Es gibt außerdem noch weitere, weniger wichtige Felder.
Innerhalb vom Lucene-Index suchen
Man sucht innerhalt von Lucene mit <Feldname>:<Bedingung>. Man kann dazu ein Wildcard "*" (0-N beliebige Zeichen) oder "?" (genau ein Zeichen) verwenden. Mehr dazu findet Ihr unter: Lucene Query Syntax. Um also zum Beispiel das oben genannte Paket zu finden, könnte man sowas in die Suche eintippen:
u:org.springframework.boot|spring-boot-starter-data-rest*...und erhält 603 Treffer, verteilt auf mehrere Seiten. Her ist das Tool ein wenig irreführend, da es mit den halbleeren Seiten den Eindruck erweckt, das wäre alles, aber oben rechts kann man die Seiten blättern.
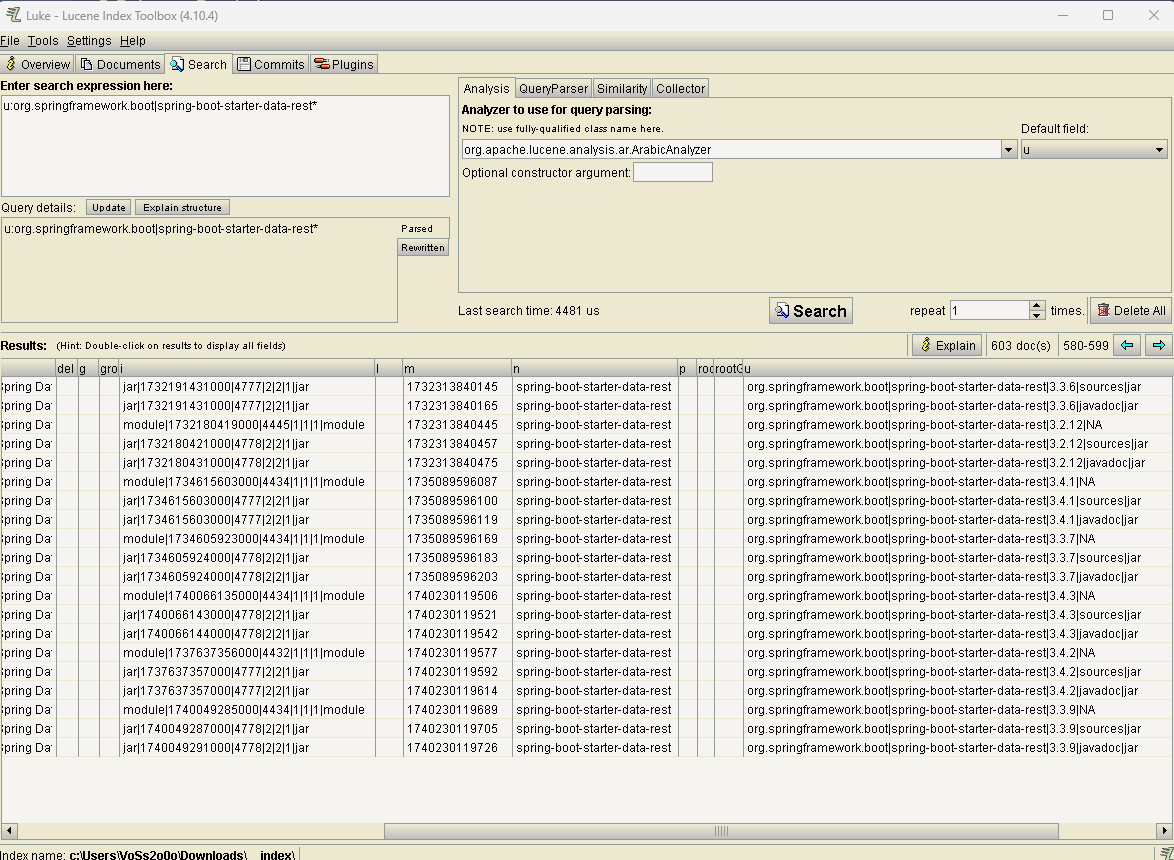
Um sich nun die details besser als in der Suchliste anzuschauen, ann man auf die Details mit doppelklick wechseln:
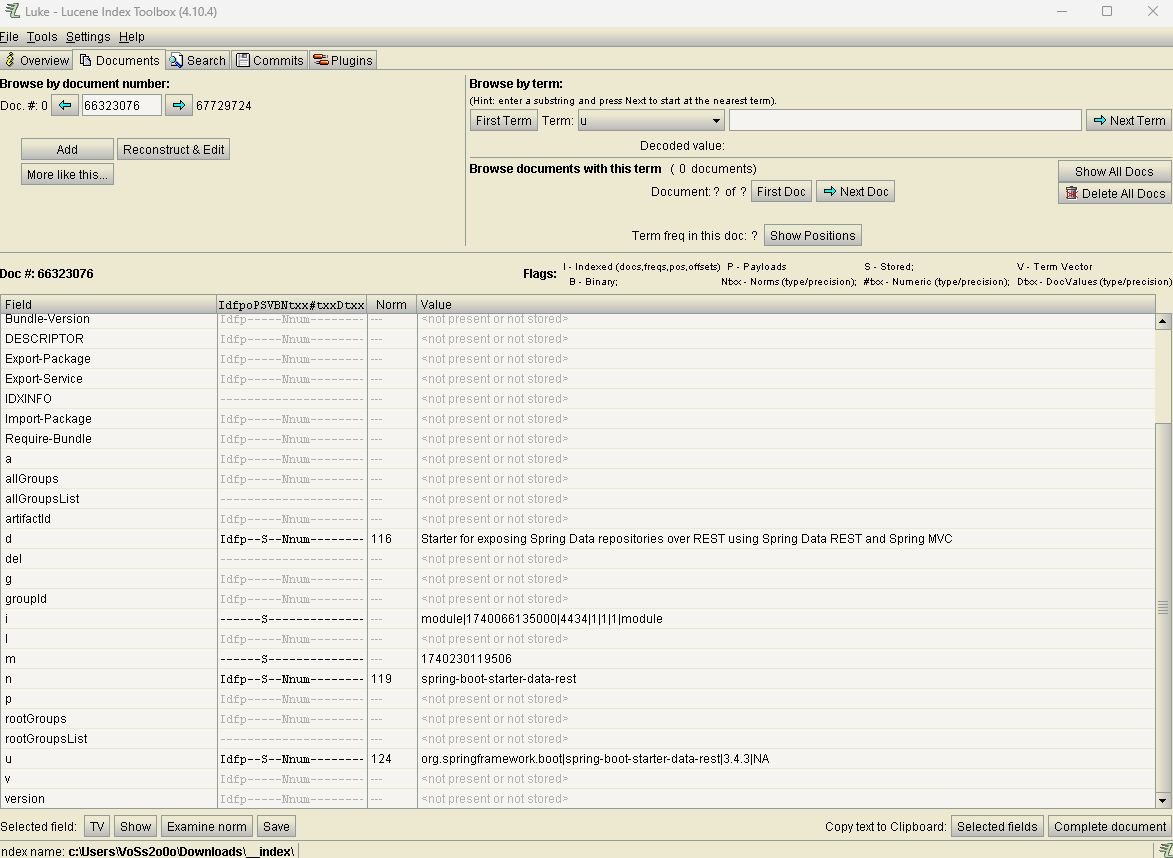
Doch wie ist das Format der beiden Formate aufgebaut?
Das Transport-Format
Mit diesen grafischen Informationen, war es nicht schwer das Format zu enträtseln. Hier einmal ein Auszug aus der Datei:
![]()
FileHeader
Zuallererst kommt ein File-Header mit von mir nicht näher erforschten Daten:
FileHeader
01 00 00 01 94 A0 97 F2 EDEs handelt sich um 9 Zeichen.
Document
Nun folgt eine Header für das erste Document. (Möglicherweise handelt es sich hier schon um Teile des nachfolgenden Teil)
DocumentHeader
00 00Nun kommt die Anzahl an Feldern, welche in diesem Document enthalten sind:
FieldsNumber
00 05Das Format ist BigEndian Es wird also wie die größte Ziffer zuerst, und die kleinste Ziffer zuletzt genannt. Die hexadezimale Fünf entspricht der dezimalen fünf. Es sind also fünf Felder, die nun folgen.
Fields
Nun kommen die Flags für das erste Feld:
FieldFlags
05Es handelt sich hierbei um ein Schlüssel zu einer Kombination aus Flags. Das zu erläutern würde hier zu weit gehen.
Es folgt die Länge des namens des Feldes:
FieldNameLength
00 01Wie weiter oben beschrieben, ist das eine Eins. Der Name ist also 1 Zeichen lang.
FieldName
75
uDer Name lautet "u", also das Feld, welches u.a. groupId und artefactId enthält.
Nun kommt der Header des Wertes (Möglicherweise handelt es sich hier schon um Teile des nachfolgenden Teil)
ValueHeader
00Und wieder folgt die Länge, diesmal aber in drei Bytes (oder 4?)
ValueLength
00 00 23Die hexadezimale 23 ist eine 35, Der Wert ist also 35 Zeichen lang:
FieldValue
78 79 7A 2E 69 63 65 74 61 6E 67 2E 6C 69 62 7C 69 6E 76 66 78 2D 63 6F 72 65 7C 33 2E 33 2E 33 7C 4E 41
xyz.icetang.lib|invfx-core|3.3.3|NADas nächste Field
Ich habe ja bereits weiter oben beschrieben, was dieser Wert bedeutet. Nun wiederholt sich das ganze, es folgt das nächste Feld (also wie hier beschreiben folgt wieder der Abschnitt "Fields", bis die beschriebene Anzahl an Feldern aufgezählt worden ist.
Das nächste Document
Unmittelbar auf das Ende des letzten Feldes, folgt nun das nächste Document, hier im Beispiel also:
Position
01 02 03 04 05 06 07 08
Wert
00 00 00 05 05 00 01 75- Also Position 1 und 2 sind der DocumentHeader,
- 3 und 4 ist die Anzahl der Felder (5),
- unter Position 5 sind die Flags vermerkt,
- unter Position 6 und 7 die länge des Fieldname,
- unter Position 8 ist nun der Feldname mit einem Zeichen Länge gespeichert ("u")
Das Lucene Format
Dieses Format ist ganz ähnlich aufgebaut, aber auf Geschwindigkeit optimiert. Zwei Dateien sind hier zum manuellen Parsen wichtig:
Die *.ftd - Datei und die *.fnm - Datei.
Die FNM-Datei
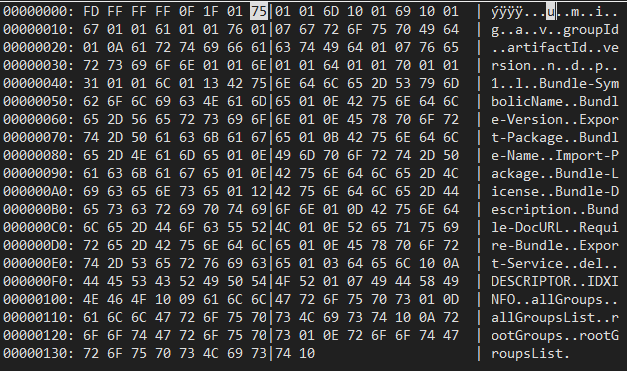
Hier sind die Spaltennamen und den darus resultierenden Index gespeichert. Die Logik ähnelt des vorangegangenen beschriebenen:
FieldHeader
FD FF FF FF 0FFieldsNumber
1F
-> 31 FelderFieldNameLength
01
-> Feldname hat 1 ZeichenFieldName
75
uDas wiederholt sich nun für die Anzahl der Felder. Am Schluss folgt dann noch ein Footer.
FileFooter
10FTD-Datei
Auch hier wieder das Format ist ähnlich der vorangegangenen, aber auf Geschwindigkeit aufgebaut.
FileHeader
00 00 00 03FieldsNumber
06
-> 6 FelderFieldsIndex
00
-> Das erste Feld (null basierend) aus der FNM-DateiValueLength
00 16FieldValue
79 6F 6D 7C 79 6F 6D 7C 31 2E 30 2D 61 6C 70 68 61 2D 32 7C 4E 41
yom|yom|1.0-alpha-2|NADas wiederholt sich nun für die Anzahl der Felder. Danach folgt sofort das nächste Document:
Position
01 02 03 04
Wert
04 00 00 16- An Position eins wieder die FieldsNumber,
- Dann wieder der FieldsIndex
- an dritter und vierter Position wieder die Länge des ersten Wertes
